大数据实战派 都爱大讲台
QQ登录
登录 / 注册
当前位置:首页 / 课程 / 大数据开发工程师特训营
分享到:
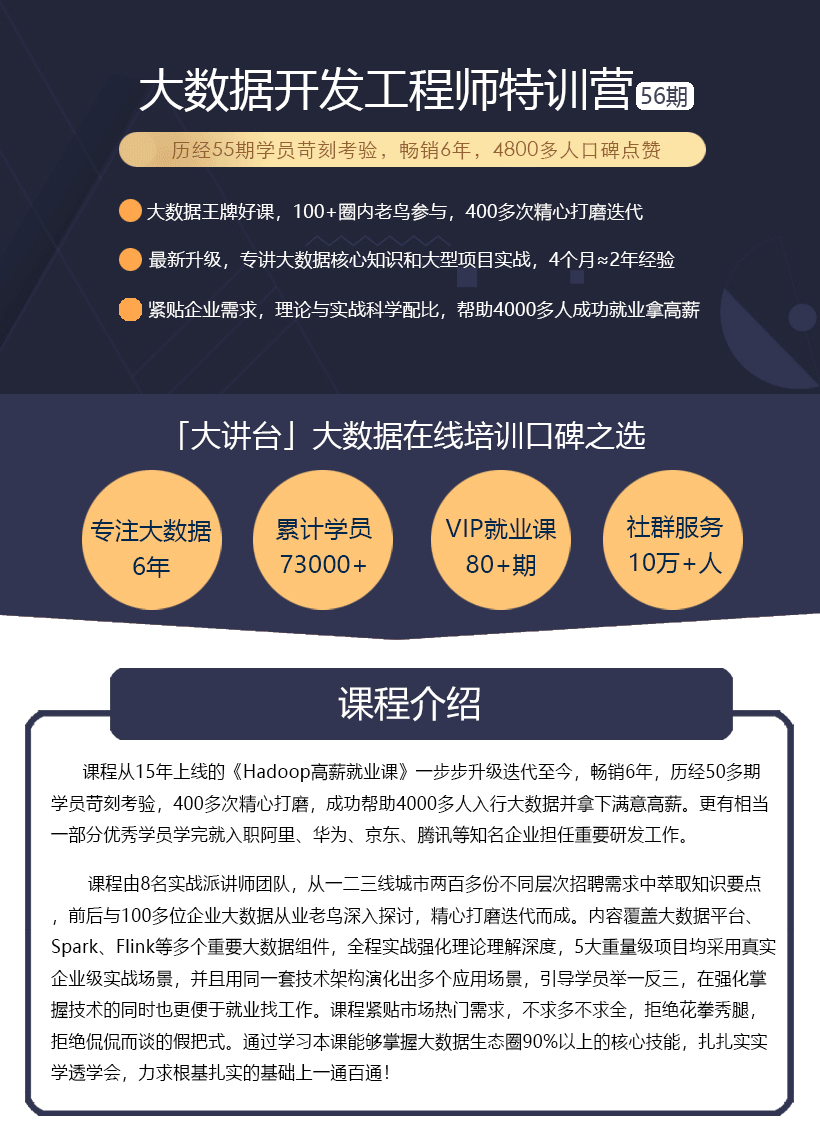
【3重优惠】 技术大牛组团授课,专讲大数据核心知识和大型项目实战,多台物理服务器数十个节点现场直播演示!企业级实战项目让你四个月掌握2年的项目经验!
¥8600 ¥8600
年底特惠 距结束: : :
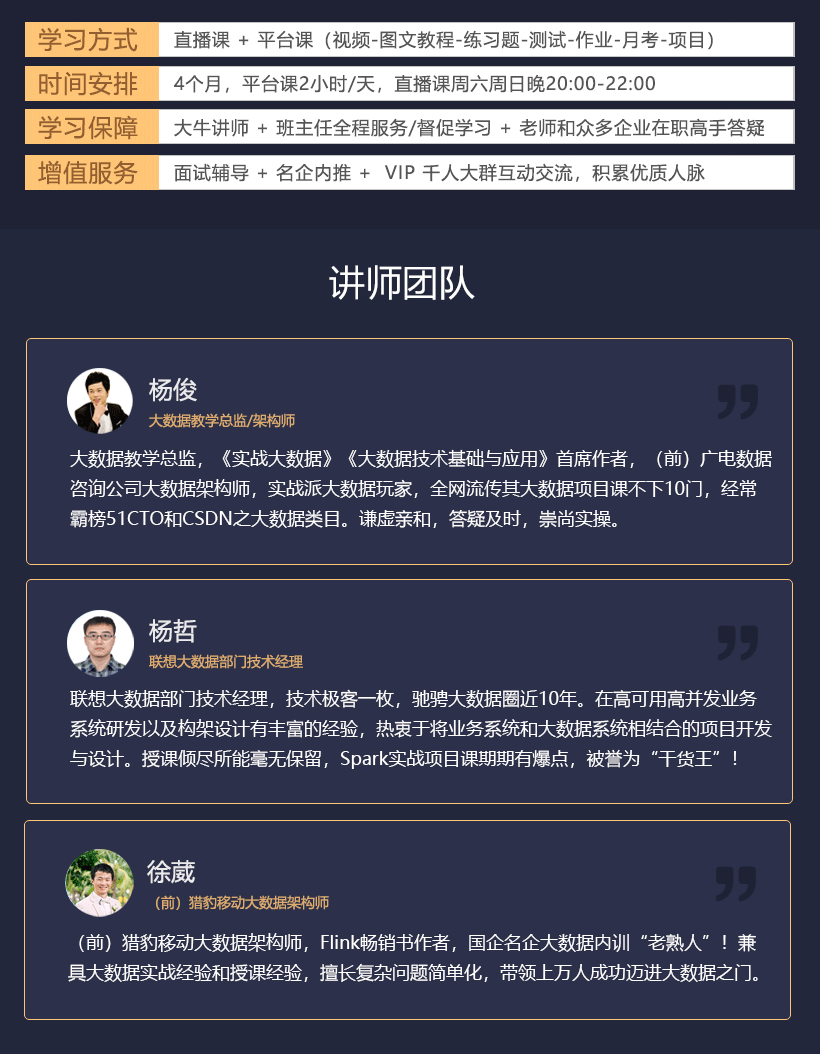
时长 16周 开班时间 56期(2月19日)
全款购买 当前学习人数 4821 人 收藏
你可能还喜欢的课程
【千元钜惠】 资深大数据架构大佬全程直播,传授硬核技能:①OLAP/HTAP/湖仓一体等多种架构;②借FlinkCDC/Kylin/Hudi/Doris等打造数仓;③湖仓一体化项目落地实践;④基于Flink和StreamX打造低代码大数据中台
查看详情 QQ咨询
大数据实战精英+架构师班
查看详情 4个月
【千元钜惠】 手握6000+节点的大数据运维大咖全程直播,4个月带你熟悉大数据集群规划、部署、监控、排错、容器化等技能,并完成3个商业项目。
大数据运维尖刀班
【优惠活动】 新东方、搜狗、腾讯等名企一线实战讲师授课,技“高”一筹!重在培养数据分析方法及思路,而不仅仅是学习技术及工具。带教多个互联网及金融领域企业真实项目,而不仅仅是讲理论和小案例。
数据分析特训营
查看详情 16周
本课程为大数据金融信贷项目实战课,着重讲解企业中常用的大数据技术理论与实战,如Hadoop、Hive、HBase、Sqoop、Flume、Kafka、Spark Streaming、Spark SQL、Spark Structured Streaming等。课程包含离线项目和实时项目,从项目业务需求、技术选型、架构设计、集群安装部署、集成开发以及项目可视化进行多方位实战讲解。
互联网金融信贷项目实战(Hadoop&Spark)
查看详情 38小时44分钟
干货多:15案例 + 3实战 + 2项目; 提升快:滴滴出行一线架构师传授实战经验,30小时多方位讲解数据仓库构建相关理论及实战内容 技术全:综合运用Hive/Flume/Kafka/Azkaban/Oozie/SparkSQL等技术;
基于大数据体系构建数据仓库
查看详情 32小时52分钟
本课程基于某电商公司运营实时分析系统(2B),对Flink进行系统讲解。通过本课程的学习,既能获得Flink企业级真实项目经验,也能深入掌握Flink的核心理论知识,还能获得Flink在生产环境中安装、部署、监控的宝贵经验,从而深入掌握Flink技术。
Flink电商运营项目实战
查看详情 50小时6分钟
他们在学
177****8856
132****2569
158****2283
梦小凡
188****8813
TOUCH
刘源
曾博士
山间日月挽和风
坏小德
君子以笙
daniel2020
26923
26837
胡羽璇
asia