
课程介绍
Felix老师主讲的Spark课程可谓千呼万唤终出来!这或许是全网首套系统的Spark就业课程,说首套是因为在我们眼里,那种把Hadoop、Spark、Storm揉在一起,零碎的这讲讲那讲讲浅尝辄止的课程算不得就业课,同时,那种连老师自己都没有真正做过Spark项目看看书就在那里讲多而全的Spark碎碎念的视频也算不得Spark就业课。
大讲台的这门《Spark高薪就业课》是一套系统且具有很强实战性的Spark课程,通俗易懂,由浅入深,基于企业项目环境,深度剖析和讲解Spark。本课程涵盖了Spark Core、Spark SQL、Spark Streaming、Spark Mllib以及Spark运维与监控、Spark相关项目等所有Spark核心内容,最后以知名手机厂商用户行为实时分析系统做为案例来详细讲解Spark并带领大家完成从理论到实战的进阶!
通过本课程深入系统的学习Spark,从事j2ee等传统软件开发工程师的同学可以转型Spark大数据开发工程师,或者正在从事Hadoop大数据开发的朋友可以拓宽自己的技术能力栈,提升自己的价值。
Spark分布式集群环境搭建视频讲解
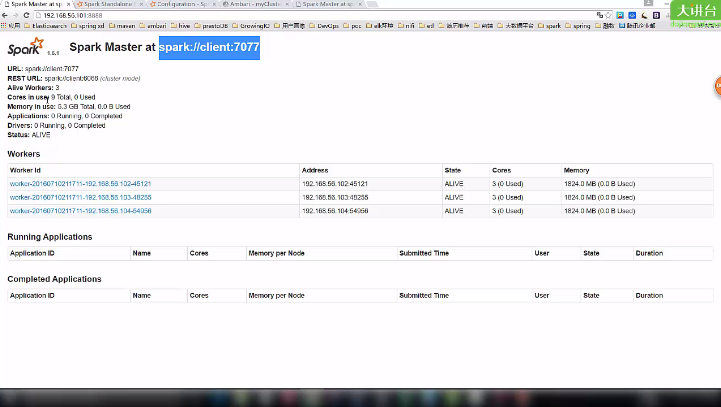
项目需求视频讲解
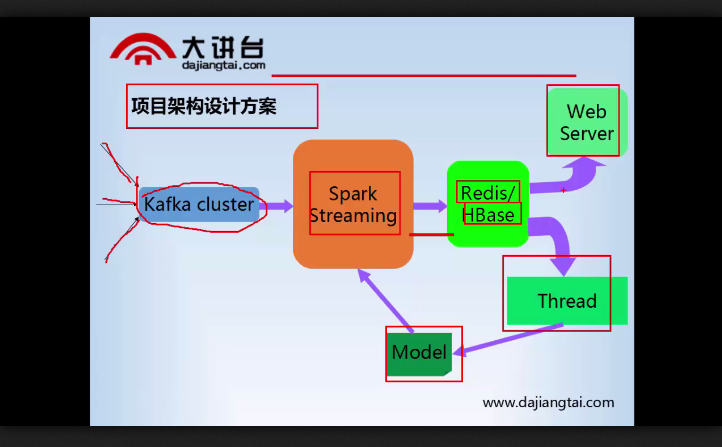
项目架构设计方案视频讲解
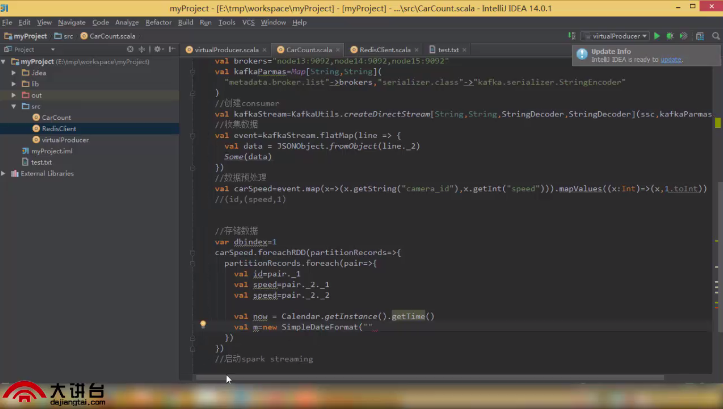
项目具体代码实现视频讲解
讲师介绍
-

Felix
大讲台大数据特聘讲师 | 北京某移动应用平台大数据高级架构师
北京某移动应用平台大数据高级架构师 10年一线开发及项目管理经验,6年以上大数据系统架构及分析处理经验,骨灰级大数据玩家。曾就职于国内某TOP5的电信相关业务公司,负责对手机信息收集处理工作
对于Hadoop、Storm、Spark有较深研究。搭建、维护过上百节点集群,处理过PB级数据。 因技术出色,多次在知名企业内部进行大数据技能培训,对一线企业大数据方面的技能需求非常了解。 热爱分享,喜欢结合切身经历的大型项目经验来授课,用血淋淋的一线案例、真刀真枪的现场演示、实时的回馈指导赢得了很多学员的仰慕和好评。
-

杨俊
大讲台大数据高级讲师 | 原某广电数据咨询公司大数据高级架构师
原某广电数据咨询公司大数据高级架构师 资深Java玩家,大数据技术狂热者。曾在北京某广电数据咨询公司担任大数据高级架构师,7年以上大数据实操经验, 经历过10个以上的重量级大数据项目。Hadoop源码级技术大咖,熟练使用Hadoop、Spark、Hive、HBase、Flume、Kafka等各大主流组件。谦虚亲和,崇尚实操至上的教学理念。受到学员一致好评。
-

杨哲
大讲台大数据特聘讲师 | 国内知名手机厂商大数据资深工程师
某大型手机厂商大数据小组Team Leader,对离线计算和实时计算都有丰富的经验。从业时间10年,曾在社交网络、移动广告、视频等行业研发大数据平台,擅长Hadoop、Flume、Kafka、Spark 、hbase大数据相关技术。在高可用高并发的业务系统的研发以及构架设计也有丰富的经验,热衷于将业务系统和大数据系统相结合的项目开发与设计。
免费视频这么多,为什么还要来大讲台?
智能化
学习任务智能推送
混合式
“图文+视频”混合式课件
答疑快
30分钟问答响应
实战多
3分理论7分实战
包学会
账号长期有效学会为止
课程大纲
| 1、Spark概述 |
1)Spark是什么 2)Spark组成---大一统的软件栈 3)Spark组成---Spark Core 4)Spark组成---Spark SQL 5)Spark组成---Spark Streaming 6)Spark组成---Spark MLlib 7)Spark组成---GraphX 8)Spark与Hadoop的关系 9)Spark的竞争对手---Flink 10)Spark的竞争对手---Storm/JStorm 11)Spark的竞争对手---Hadoop3.x |
| 2、Spark生态系统 |
1)Spark自有生态圈(以Spark为核心) 2)Spark 之外更大的生态圈 3)如何学习Spark |
| 3、Spark 编程实例 |
1)Wordcount之Java版 2)Wordcount之Scala版 |
| 1、Spark源码编译 |
1)Spark版本选择 2)Spark下载—Apache版本 3)Spark下载—CDH版本 4)Spark下载—HDP版本 5)Spark build参考文档 6)下载Spark源代码 |
| 2、Spark最简安装 |
1)Spark预编译安装包下载—apache版 2)Spark目录详解 3)Spark最简安装 4)运行spark自带实例程序 |
| 3、Spark编程环境搭建 |
1)基于Intellij IDEA搭建Spark开发环境搭—参考文档 2)基于Intellij IDEA搭建Spark开发环境—maven vs sbt 3)基于Intellij IDEA搭建Spark开发环境搭—maven构建scala项目 4)基于Intellij IDEA搭建Spark开发环境搭—spark依赖 5)基于Intellij IDEA搭建Spark开发环境搭—打包插件 6)Spark 实例程序开发 7)Spark 项目的打包与运行 |
| 4、Spark 编程模型 |
1)Spark 核心概念详解 2)Spark Application的组成 3)Spark Application基本概念 4)Spark Application编程模型 5)RDD的概念 6)RDD接口 7)RDD的本质特征 8)RDD--partitions、RDD-preferredLocations、dependencies、compute、partitioner、lineage 9)典型RDD的特征 10)不同角度分析RDD 11)Scheduler Optimizations 12)如何创建RDD 13)RDD transformation操作 14)RDD 控制操作 15)RDD action操作 16)创建Pair RDD 17)Pair RDD transformation操作 18)Pair RDD action操作 19)Pair RDD 分区控制 |
| 5、Spark运行模式概述 |
1)解析Application program的组成部分 2)Spark 运行流程详解 3)Spark 具体执行流程 4)Spark 任务调度 5)Spark DAGScheduler 6)Spark TaskScheduler 7)Spark ScheduleBacked 8)Spark 作业详细执行过程 9)Spark 实例解析 10)Spark 各种运行模式详解 |
| 6、Spark Standalone运行模式 |
1)Spark Standalone架构 2)手工启动Spark集群 3)通过脚本启动Spark集群 4)访问Web UI查看Spark集群 5)Job提交与运行 6)Spark Standalone HA高可用实现 7)Spark基本工作流程 8)Spark local模式 9)Spark local cluster模式 10)Spark standalone模式 11)Spark standalone详细过程解析 12)Spark Standalone 实例操作 |
| 7、Spark on YARN |
1)YARN是什么 2)YARN在Hadoop生态系统中的位置 3)YARN产生的背景 4)YARN基本架构 5)Spark on YARN配置与部署 6)spark-shell运行在YARN上 7)提交Spark Job给YARN 8)Spark on YARN运行架构解析 9)Spark on YARN配置详解和注意事项 |
| 1、Spark交互式工具spark-shell |
1)Spark REPL 2)Spark shell 3)spark-shell运行在YARN上 |
| 2、Spark应用程序部署工具spark-submit |
1)打包Spark Application 2)使用spark-submit启动Spark Application 3)spark-submit 各种使用方式详解 4)spark-submit option各种配置选项详解 |
| 3、Spark存储管理机制 |
1)存储管理概述 2)RDD控制操作 3)RDD持久化级别 4)如何选择持RDD久化级别 5)缓存淘汰机制 6)Shuffle数据持久化 7)广播变量和累加器 |
| 4、Spark多语言编程 |
1)Spark多语言编程特点 2)Spark 编程模型 3)深入Spark 多语言编程 4)Spark 多语言编程综合实例 |
| 1、Spark SQL概述 |
1)Spark SQL是什么? 2)何为结构化数据 3)SparkSQL 与 Spark Core的关系 4)Spark SQL前世今生:由Shark发展而来 5)Spark SQL前世今生:可以追溯到Hive 6)Spark SQL前世今生:Hive 到 Shark 7)Spark SQL前世今生:Shark 到 Spark SQL 8)Spark SQL前世今生:Hive 到 Hive on Spark |
| 2、Spark SQL基本原理 |
1)Spark SQL模块划分 2)Spark SQL架构--catalyst设计图 3)Spark SQL运行架构 4)Hive兼容性 |
| 3、Spark SQL编程详解 |
1)SparkSQL的依赖 2)SparkSQL的入口:SQLContext 3)SparkSQL的入口: HiveContext 4)SQLContext vs HiveContext 5)Spark SQL的作用与使用方式 6)Spark SQL支持的API 7)从程序中使用SparkSQL的基本套路 8)DataFrame—推荐使用 9)为什么要用DataFrame 10)SparkSQL数据源:从各种数据源创建DataFrame 11)SparkSQL数据源:RDD 12)SparkSQL数据源:Hive 13)SparkSQL数据源:Hive读写 14)SparkSQL数据源:访问不同版本的metastore 15)SparkSQL数据源:Parquet 16)SparkSQL数据源:Json 17)SparkSQL数据源:JDBC |
| 4、Spark SQL分布式SQL引擎 |
1)SparkSQL分布式查询引擎:两种实现方式 2)SparkSQL分布式查询引擎:Thrift JDBC/ODBC服务 3)SparkSQL分布式查询引擎:beeline 4)SparkSQL分布式查询引擎:Spark SQL CLI |
| 5、Spark SQL用户自定函数 | 1)注册UDF |
| 6、Spark SQL性能调优 |
1)开启缓存数据功能 2)参数调优 |
| 1、Spark Streaming概述 |
1)批处理 & 流处理 2)为什么需要流处理---更多场景需要 3)Spark Core & RDD本质上是离线运算 4)Spark Streaming是什么 5)Spark Streaming的竞争对手 6)Spark Streaming vs Storm |
| 2、Spark Streaming 实例操作 | 1)Spark Streaming 实例操作 |
| 3、SparkStreaming运行原理与核心概念 |
1)SparkStreaming运行原理 2)SparkStreaming的高层抽象DStream 3)Dstream与RDD的关系 4)Batch duration |
| 4、SparkStreaming编程模型 |
1)依赖管理 2)编程基本套路 3)Dstream输入源---input DStream 4)Dstream输入源--- Receiver 5)内置的input Dstream:Basic Sources 6)内置的input Dstream:Advanced Sources 7)Dstream输入源:multiple input DStream 8)Dstream输入源:Custom Receiver 9)无状态转换操作 10)有状态转换操作1-updateStateByKey 11)有状态转换操作2-window操作—普通规约与增量规约 12)有状态转换操作2-window操作—理解增量规约 13)DStream输出 14)持久化操作 |
| 5、SparkStreaming性能调优 |
1)合理的并行度 2)减少任务启动开销 3)选择合适的batch Duration 4)内存调优 5)设置合理的cpu数 |
| 6、Spark Streaming容错 |
1)检查点机制-checkpoint 2)Driver节点容错 3)Worker节点容错 4)处理保证 |
| Spark运维与监控 |
1、Spark On YARN 2、Spark 查看Job History日志 3、Spark JobServer部署 4、Spark 监控 5、Spark UI监控 |
| 一、需求分析 |
1.1背景 1.2总体要求 1.3难点分析 1.4解决问题的思路 |
| 二、知识要点 |
2.1Flume要点 2.2Kafka要点 2.3spark-streaming要点 2.4Hbase要点 |
| 三、难点攻克 |
3.1难点攻克1:如何收集不同业务系统的日志 3.2难点攻克2:数据容错和提高并发处理能力 3.3难点攻克3:减少写hbase的读写次数 |
| 四、解决方案设计 |
4.1技术选型 4.2架构设计 4.3部署方案 4.4业务日志采集 |
| 五、集群部署 |
1、Zookeeper集群 2、Hadoop YARN集群 3、Hbase集群 4、Kafka集群 5、Spark 集群 |
| 六、业务实现 |
6.1模拟搭建业务系统 6.2Flume采集agent 6.3Flume聚合agent 6.4编写Spark-streaming程序 6.5Hbase Java访问数据 6.6spark程序提交 |
| 七、项目总结 | 大数据项目需要综合运用各种技术 |
| Spark基础之Scala编程语言实战 |
1、Scala 简介 2、Scala安装及环境配置 3、Scala 开发环境搭建 4、Scala 基础语法 5、Scala 数据类型 6、Scala 变量 7、Scala访问修饰符 8、Scala 运算符 9、Scala IF...ELSE 语句 10、Scala 循环 11、Scala 数组 12、Scala 字符串 13、Scala 类和对象 14、Scala 类的构造器 15、Scala Object对象 16、Scala Apply和Unapply方法 17、Scala 的继承 18、Scala 特征Trait 19、Scala 文件 I/O 20、Scala包的定义与使用 21、Scala 函数声明 22、Scala 函数定义 23、Scala 函数调用 24、Scala 闭包 25、Scala 柯里化 26、Scala 高阶函数 27、Scala 集合 28、Scala Iterator迭代器 29、Scala 模式匹配 30、Scala 样例类 31、Scala 提取器(Extractor) 32、Scala 正则表达式 33、Scala 异常处理 34、Scala 编写第一个Spark程序 |



















