
课程特色
1、基于经典的电影推荐系统进行全面的讲解
2、使用大数据业内流行的Spark框架实现电影推荐系统
3、运用数据挖掘的算法产生模型,为用户精准推荐喜好的电影
4、分别通过离线和实时两种方式实现电影推荐系统
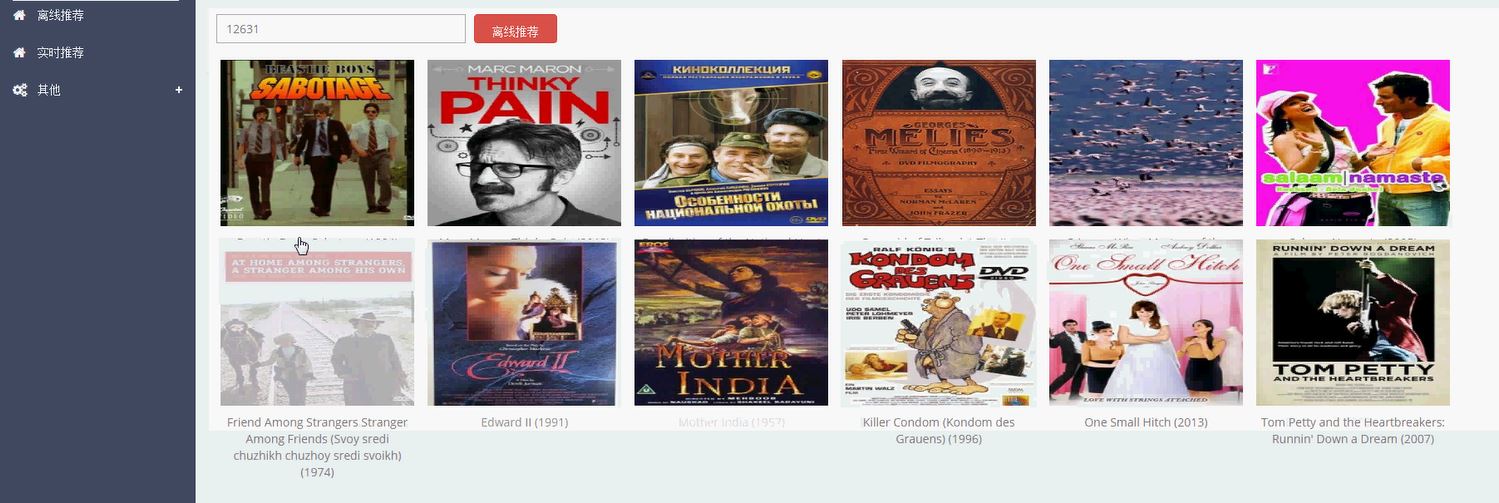
部分项目效果图
部分代码图
项目涉及技术
Spark Core,Spark Streaming,Spark Mlib,Hadoop,Linux,Scala,Kafka,Hbase,Phoenix
Spark:基于内存的分布式计算框架
Hadoop:分布式离线计算框架
Kafka:分布式高并发消息队列,负责缓存Flume采集的数据并为下游的各种计算提供高并发的数据处理
Hbase:亿级行百万列并可毫秒级查询的数据库,可快速查询我们的计算数据
Phoenix:是构建在HBase上的SQL中间层,Phoenix查询引擎会将SQL查询转换为一个或者多个HBase Scan,并行执行以生成标准的JDBC结果集。
适用人群
1、大数据技术爱好者及从业人员。
2、有hadoop基础缺少推荐项目经验的学员
3、有spark基础缺少推荐项目经验的学员
课程目标
1、 学会使用spark来实际分析处理数据的思路和方法,以及如何把原始数据整理成结构化的数据
2、 学会如何把数据集切分成训练集,验证集,训练模型,寻找最佳的模型。
3、 使用模型,通过离线和实时的方式得到推荐结果。
4、 在分布式的环境下实际运行和调试我们的程序。
5、 掌握在开发和调试过程中,遇到的各种问题的解决思路和方法。
讲师介绍
-

罗辉
北京航空航天大学云计算专业硕士研究生
IT类工作10年以上经验, 熟练使用Spark和hadoop生态圈的技术,熟练使用Scala和shell。有架构设计能力,能自主设计以Spark为主的大数据应用架构。 12年开始接触hadoop技术,14年专业从事spark技术研究与开发,目前在某企业里从事spark数据开发的相关工作,曾负责企业的spark内训,主讲spark部分。
1、在2014年夏作为Hadoop培训讲师,曾参与过广州汇丰软件公司的高级Hadoop课程(Hbase,Spark)培训讲授。
2、作为特邀嘉宾曾参与EASYHADOOP社区14年11月北京线下活动,演讲《spark介绍及SPARKSQL应用》。
3、另外完成和知名IT培训网站北风网和PPV网合作的spark培训的视频。
4、在2016年3月通过了Databricks的Develop Certification for Apache Spark认证。
5、2016年6月~7月作为红象云腾外聘讲师参与联想ITBT部门的spark培训项目。
6、2016年7月开始带领5人团队参加IBM Spark大赛,研发基于Spark的数据挖掘产品。
7、2016年9月独立完成对广州汇丰银行5天的hadoop&spark培训。
课程大纲
| 1、项目总体介绍和背景 | a.基于Spark流行的大数据工具,开发一套电影推荐系统,让大家体验到如何实现自己的“猜你喜欢”的推荐。 很多电商和购物网站以及一些手机上的应用,猜你喜欢已经成为了必备功能,它对网站的销售有着很明显的刺激作用。 |
| 2、技术框架 | a.大数据工具的选择,包括HDFS、HIVE、SPARK、KAFKA、HBASE、PHOENIX、ZEPPELIN等工具。 b.推荐的实时性,包括实时推荐和离线推荐。 |
| 3、系统要求以及开发的重点和难点 | a. 完成一个推荐系统,为每个用户产生合适的电影产品的推荐结果。并且满足在性能,可靠性上的要求。 b. 实时数据的产生以及打到kafka消息队列中。 c. 对数据特征的发掘、清洗和加工。 d. 产生推荐系统的模型,并在多个模型中选择最佳的模型。 e. 解决整个系统中的性能问题。 |
| 4、集群准备 | a.
搭建hadoop、hive、spark、kafka、zookeeper、hbase、phoenix、ZEPPELIN集群 b. 安装MYSQL,配置Hive metastore。 |
| 5、开发环境准备 | a.在eclipse中构建项目,通过Maven来管理项目,并添加相关的依赖。 |
| 6、项目数据准备 | a. 下载数据 |
| 1、分析数据的特点 | a. 介绍各个文件的作用以及用户和电影的各个属性 b. 分析数据区间、特点 c. 探讨开发的思路 |
| 2、数据入HDFS,通过SPARKSQL整理成表 | a. 构建RDD b. 定义各个表对应的case class c. 将RDD转换成DATAFRAME d. 在sparksql中创建对应的表 e. 通过sparksql做一些查询来验证 |
| 3、数据集的准备 | a. 字段剖析 b. 选择合适的字段将数据切分成测试集和验证集 |
| 1、数据加工,整理出rating | a. 通过一系列的数据转换形成rating数据 |
| 2、依据ratings构建模型 | a. 构建模型 |
| 3、理论补充 | a. ALS算法的介绍 |
| 4、最佳参数的寻找 | a. 评估模型好坏的指标RMSE b. 模型相关的参数 c. 如何寻找最好的模型 |
| 5、离线推荐 | a. 依据输入的某个用户ID,加载模型,产生推荐的电影结果,写入到数据库中 b. 依据输入的某个电影,加载模型,给出可能喜欢的用户 |
| 1、构建实时数据流 | a. 将ratings表里的数据通过模拟的方式打入到kafka的消息队列中。 |
| 2、在sparkstreaming中接收kafka消息队列中的数据,开发实时数据处理模块 | a. 在sparkstreaming通过direct的方式来接收kakfa中的数据,然后加载已经存在的模型,实时生成推荐结果,写入到数据库中。 |
| 3、新用户或者未登录用户 | a. 推荐策略的推想,以及实现用户的推荐。 |
| 1、系统稳定性的考虑 | a. 开发脚本来保证实时应用的持续运行。 |
| 2、数据的展示 | a. 通过Zeppelin来连接sparkSQL,提供一个方面快捷的数据探查的系统 |
| 3、探索其他的算法在推荐系统中可能的用处 | a. 其他算法的介绍和应用 |
| 1、项目总结 | a. 与大家一块探讨整个系统开发过程中的感受,对系统的理解,需求的理解,各个组件的理解。 |
| 2、技术探讨 | a. 与学生一起探讨整个系统还可以从哪些方向去做改进,如果做改进。架构,性能,推荐的准确性,实时性,系统稳定性,安全性。 |
常见问题
Q:会有实际上机演示和动手操作吗?
A:本课程为项目拆解课,全程实操演练!不仅仅是简单演示,而是手把手带你操练真实项目。
Q:在线直播课程怎么答疑?
A: 每个班级会建立专门的班级QQ群,学员可以针对课程中的问题,或者自己学习与动手实践中的问题,向老师提问,老师会进行相应解答。同时,强烈推荐大家到官网技术问答区提问,方便知识的沉淀,同时也避免因为QQ群信息刷屏而导致你的问题被老师错过。

















