
课程介绍
本项目基于某新闻网用户日志分析系统进行讲解,使用目前最新的Spark2.2版本,本项目通过超长的150课时逐步讲解,从项目的需求分析到基础环境搭建,然后到核心组件项目核心知识讲解,最后到项目业务实现、可视化以及项目的总结,整个过程无论是集群环境还是业务代码,都会带着大家一步一步操作,从而全方位的、完整的掌握Spark 新闻网大数据实时分析可视化系统。
本课程值得学习的四大理由:
1. 以新闻网大数据实时分析及可视化项目为主线,从零开始讲解项目需要的各方面知识,再到项目最终实现,非常详尽实用。
2. 采用最新的Spark2.2版本,网上此类项目属“罕见”。
3. 华为资深架构师讲授 & 答疑,除了项目本身,方案、思路、眼界、大数据认知等方面都能有所收获。
4. 超过150课时,课程内容进行了居多拓展,涉及大数据多方面的技能讲解,堪称迷你型的 spark 就业课程。
涉及技术
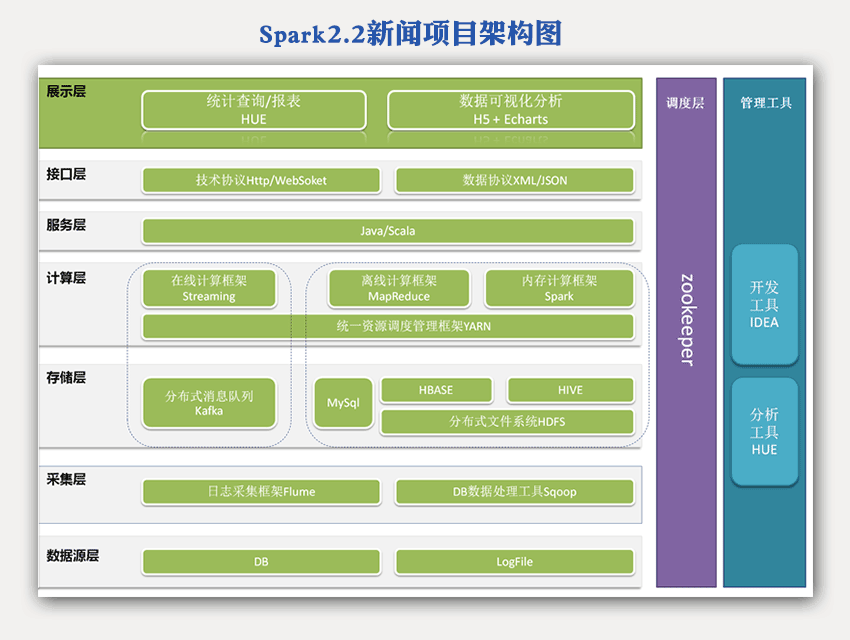
Hadoop2.x、Zookeeper、Flume、Hive、Hbase、Kafka、Spark2.2、SparkStreaming、SparkSQL、StructuredStreaming、MySQL、Hue、J2EE、websoket、Echarts
课程目标
学完本课程可胜任如下三个岗位:
1.Hadoop开发工程师
2.大数据架构师
3.Spark开发工程师
适用人群
1、大数据技术爱好者及从业人员。
2、有hadoop基础缺少项目经验的学员
3、有spark基础缺少项目经验的学员
服务
1、提供Spark项目交流群:413581066
2、提供Spark项目答疑服务
3、提供与Spark项目老师交流机会
讲师介绍
-

曹金博
大讲台大数据特聘讲师 | 华为大数据高级架构师
华为大数据架构师,曾主导过交通、电信、电商等多行业大数据项目,具有6年以上大数据项目的架构设计与研发。并且一直从事企业级大数据项目的架构设计、大数据技术研究和培训教育工作,具有丰富的大型项目实战经验以及教育培训经验。
免费视频这么多,为什么还要来大讲台?
智能化
学习任务智能推送
混合式
“图文+视频”混合式课件
答疑快
30分钟问答响应
实战多
3分理论7分实战
包学会
账号长期有效学会为止
课程大纲
| 1. Hadoop2.X版本下载及安装 2. Hadoop2.X分布式集群配置 3. 分发到其他各个机器节点 4. HDFS启动集群运行测试 5. YARN集群运行MapReduce程序测试 6. 配置集群中主节点到各个机器的SSH无密钥登录 |
| 1. HDFS-HA架构原理介绍 2. HDFS-HA 详细配置 3. HDFS-HA 服务启动及自动故障转移测试 4. YARN-HA架构原理介绍 5. YARN-HA 详细配置 6. YARN-HA 服务启动及自动故障转移测试 |
| 1. 下载HBase版本并安装 2. 分布式集群的相关配置 3. 启动依赖于Zookeeper和HDFS的两个服务 4. 通过shell测试数据库 5. 日志信息存储需求分析及表的创建 |
|
1. 下载Flume源码并导入Idea开发工具 2. 根据业务需求做采集入库的程序设计 3. 自定义SinkHBase程序开发 4. idea程序打包并部署 5. 官方Flume与HBase集成的参数介绍 6. Flume agent-3聚合节点与HBase集成的配置 7. 官方Flume与Kafka集成的参数介绍 8. Flume agent-3聚合节点与Kafka集成的配置 |
|
1. idea工具开发数据生成模拟程序 2. 编写启动Flume服务程序的shell脚本 3. 启动Flume采集相关的所有服务 4. 编写脚本并启动Flume agent三台采集节点服务 5. 编写Kafka consumer执行脚本并运行 6. java开发业务数据生成模拟器 7. 运行模拟程序并通过HBase shell检查数据 |
|
1.Hive 概述 2.Hive 架构设计 3.Hive 应用场景 4.Hive 安装部署 5.Hive与MySQL集成 6.Hive 服务启动与测试 7.根据业务创建表结构 8.Hive与HBase集成进行数据离线分析 |
|
1.Hue概述 2.Hue安装部署 3.Hue基本配置与服务启动 4.Hue与HDFS集成 5.Hue与YARN集成 6.Hue与Hive集成 7.Hue与MySQL集成 8.Hue与HBase整合 9.对采集的数据进行可视化分析 10.Hue使用的经验总结 |
| 1.Spark 概述 2.Spark 生态系统介绍 3.Spark2.X学习注意事项 4.Spark2.2源码下载及编译 5.Scala安装及环境变量设置 6.Spark2.2本地模式运行测试 7.Spark服务WEB监控页面 |
| 1.Windows开发环境配置与安装 2.IDEA Maven工程创建与配置 3.开发Spark Application程序并进行本地测试 4.打Jar包并提交spark-submit运行 |
| 1.三大弹性分布式数据集介绍 2.Spark RDD概述与创建方式 3.Spark RDD五大特性 4.Spark RDD操作方式及使用 5.DataFrame创建方式及功能使用 6.DataSet创建方式及功能 7.数据集之前的对比与转换 |
|
1.Spark SQL概述及特点 2.Spark SQL服务架构 3.Spark SQL与Hive集成(spark-shell) 4.Spark SQL与Hive集成(spark-sql) 5.Spark SQL之ThirftServer和beeline使用 6.Spark SQL与MySQL集成 7.Spark SQL与HBase集成 |
|
1.Spark Streaming功能介绍 2.NC服务安装并运行SparkStreaming 3.Spark Streaming服务架构及工作原理 4.Spark Streaming编程模型 5.Spark Streaming读取Socket流数据 6.Spark Streaming结果数据保存到外部数据库 7.SparkStreaming与Kafka集成进行数据处理 |
| 1.Structured Streaming 概述及架构 2.Structured Streaming 编程模型 3.实时数据处理业务分析 4.Stuctured Streaming 与Kafka集成(一) 5.Stuctured Streaming 与Kafka集成(二) 6.Stuctured Streaming 与MySQL集成 7.基于结构化流完成业务数据实时分析(一) 8.基于结构化流完成业务数据实时分析(二) 9.基于结构化流完成业务数据实时分析(三) |
















