大讲台spark培训之Spark知识体系完整分析
 解宝明2017/03/29
解宝明2017/03/29

首先spark是什么?Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。
Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
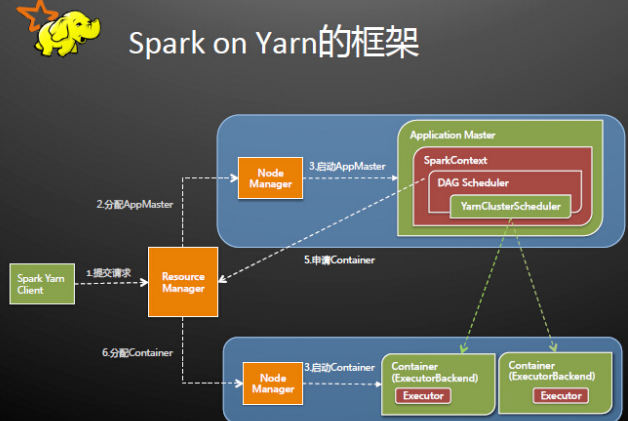
根据yarnConf来初始化yarnClient,并启动yarnClient,创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足则抛出IllegalArgumentException;
设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置Application其中的环境变量、创建Container启动的Context等;
设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
运行ApplicationMaster的run方法;
设置好相关的环境变量。
创建amClient,并启动;
在SparkUI启动之前设置SparkUI的AmIpFilter;
在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext;
等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
当SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster
分配并启动Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。
那么这个Application将失败,将ApplicationStatus标明为FAILED,并将关闭SparkContext。其实,启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的。
最后,Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到运行完成。
三、Spark节点的概念
1、Spark驱动器是执行程序中的main()方法的进程。它执行用户编写的用来创建SparkContext(初始化)、创建RDD,以及运行RDD的转化操作和行动操作的代码。
驱动器节点driver的职责:把用户程序转为任务task(driver),Spark驱动器程序负责把用户程序转化为多个物理执行单元,这些单元也被称之为任务task,为执行器节点调度任务(executor),spark驱动器在各个执行器节点进程间协调任务的调度。
2、执行器节点负责运行组成Spark应用的任务,并将结果返回给驱动器进程;通过自身的块管理器(blockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在执行器进程内的,因此任务可以在运行时充分利用缓存数据加快运算。
所有的Spark程序都遵循同样的结构:程序从输入数据创建一系列RDD,再使用转化操作派生成新的RDD,最后使用行动操作手机或存储结果RDD,Spark程序其实是隐式地创建出了一个由操作组成的逻辑上的有向无环图DAG。当驱动器程序执行时,它会把这个逻辑图转为物理执行计划。
这样Spark就把逻辑计划转为一系列步骤(stage),而每个步骤又由多个任务组成。这些任务会被打包送到集群中。
四、Spark初始化
每个Spark应用都由一个驱动器程序来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,以及对该分布式数据集应用了相关操作。
驱动器程序通过一个SparkContext对象来访问spark,这个对象代表对计算集群的一个连接。(比如在sparkshell启动时已经自动创建了一个SparkContext对象,是一个叫做SC的变量。
一旦创建了sparkContext,就可以用它来创建RDD。比如调用sc.textFile()来创建一个代表文本中各行文本的RDD。(比如vallinesRDD=sc.textFile(“yangsy.text”),valspark=linesRDD.filter(line=>line.contains(“spark”),spark.count())
执行这些操作,驱动器程序一般要管理多个执行器,就是我们所说的executor节点。
在初始化SparkContext的同时,加载sparkConf对象来加载集群的配置,从而创建sparkContext对象。
从源码中可以看到,在启动thriftserver时,调用了spark-daemon.sh文件,该文件源码,加载spark_home下的conf中的文件。
(在执行后台代码时,需要首先创建conf对象,加载相应参数,valsparkConf=newSparkConf().setMaster("local").setAppName("cocapp").set("spark.executor.memory","1g"),valsc:SparkContext=newSparkContext(sparkConf))
五、Spark数据分区
Spark的特性是对数据集在节点间的分区进行控制。在分布式系统中,通讯的代价是巨大的,控制数据分布以获得最少的网络传输可以极大地提升整体性能。Spark程序可以通过控制RDD分区方式来减少通讯的开销。
Spark中所有的键值对RDD都可以进行分区。确保同一组的键出现在同一个节点上。比如,使用哈希分区将一个RDD分成了100个分区,此时键的哈希值对100取模的结果相同的记录会被放在一个节点上。
六、SparkSQL的shuffle过程
SparkSQL的核心是把已有的RDD,带上Schema信息,然后注册成类似sql里的”Table”,对其进行sql查询。这里面主要分两部分,一是生成SchemaRD,二是执行查询。
如果是spark-hive项目,那么读取metadata信息作为Schema、读取hdfs上数据的过程交给Hive完成,然后根据这俩部分生成SchemaRDD,在HiveContext下进行hql()查询。
七、SparkSQL结构化数据
首先说一下ApacheHive,Hive可以在HDFS内或者在其他存储系统上存储多种格式的表。SparkSQL可以读取Hive支持的任何表。要把SparkSQL连接已有的hive上,需要提供Hive的配置文件。hive-site.xml文件复制到spark的conf文件夹下。再创建出HiveContext对象(sparksql的入口),然后就可以使用HQL来对表进行查询,并以由行足证的RDD的形式拿到返回的数据。
创建Hivecontext并查询数据
importorg.apache.spark.sql.hive.HiveContext
valhiveCtx=neworg.apache.spark.sql.hive.HiveContext(sc)
valrows=hiveCtx.sql(“SELECTname,ageFROMusers”)
valfitstRow–rows.first()
println(fitstRow.getSgtring(0))//字段0是name字段
通过jdbc连接外部数据源更新与加载
Class.forName("com.mysql.jdbc.Driver")
valconn=DriverManager.getConnection(mySQLUrl)
valstat1=conn.createStatement()
stat1.execute("UPDATECI_LABEL_INFOsetDATA_STATUS_ID=2,DATA_DATE='"+dataDate+"'whereLABEL_IDin("+allCreatedLabels.mkString(",")+")")
stat1.close()
//加载外部数据源数据到内存
valDIM_COC_INDEX_MODEL_TABLE_CONF=sqlContext.jdbc(mySQLUrl,"DIM_COC_INDEX_MODEL_TABLE_CONF").cache() valtargets=DIM_COC_INDEX_MODEL_TABLE_CONF.filter("TABLE_DATA_CYCLE="+TABLE_DATA_CYCLE).collect
如果你觉得本文对你有所帮助,请关注大讲台官网、微信等平台,大讲台IT职业在线学习教育平台为您提供权威的大数据Spark培训课程和视频教程系统,通过大讲台金牌讲师在线录制的第一套自适应Spark在线视频课程系统,让你快速掌握Spark从入门到精通大数据开发实战技能、
 分享到QQ空间
分享到QQ空间 分享到微信
分享到微信 分享到QQ好友
分享到QQ好友
看完这篇文章的人大多学习了更多课程>>






