
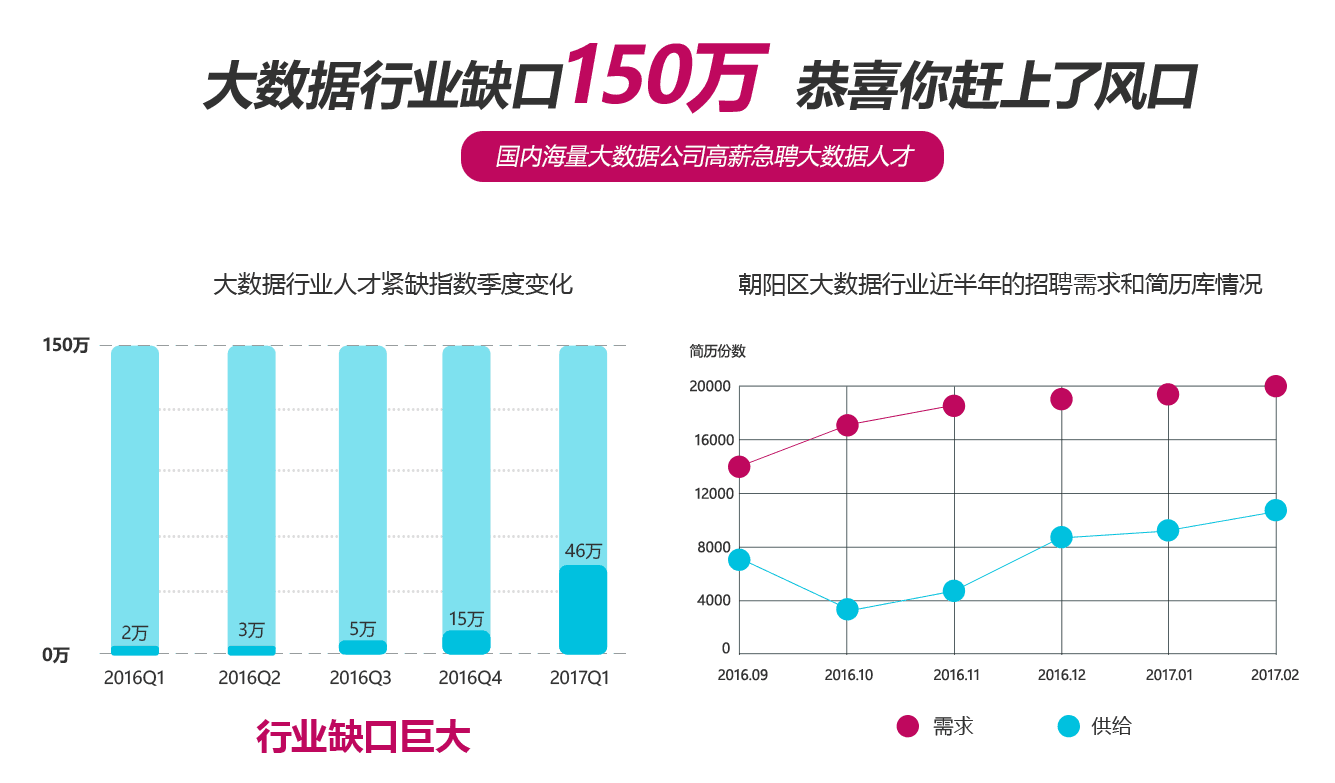
全世界知名企业都在·疯狂寻找大数据人才
大数据行业缘何能轻松年薪30W,只因未来3-5年需求总量达180万,目前人才缺口至少有140万。














大数据人才供不应求平均起薪已经飙到15000元
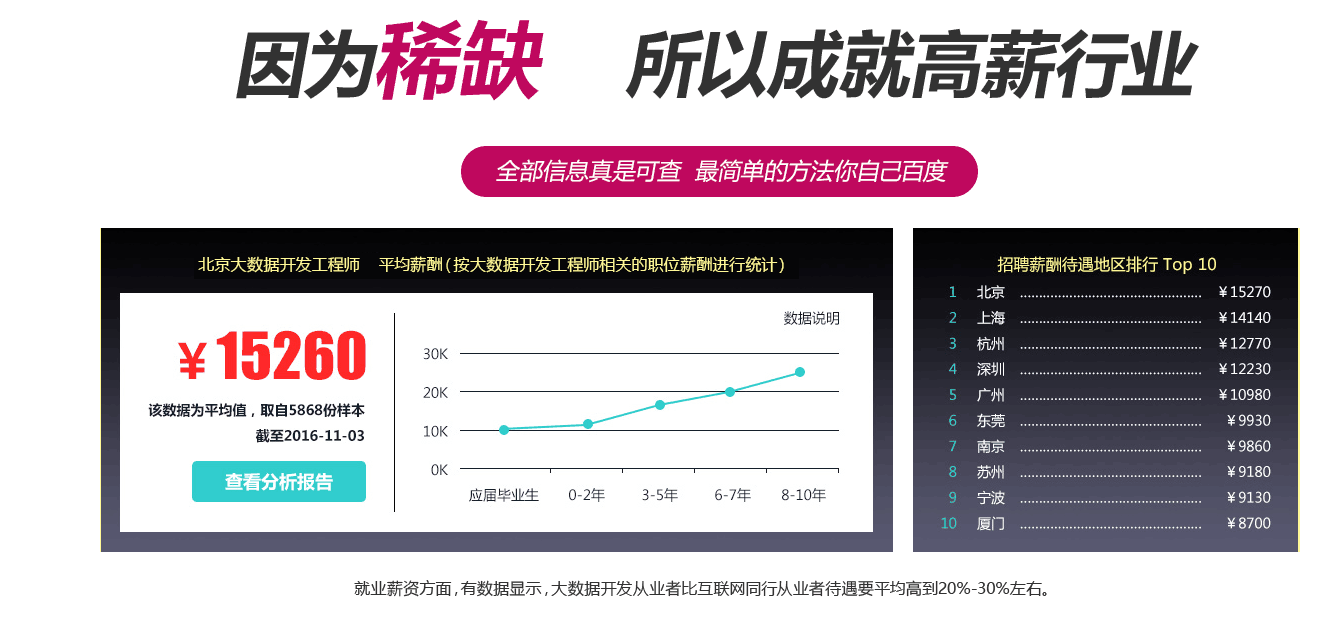
北京大数据·工资收入水平
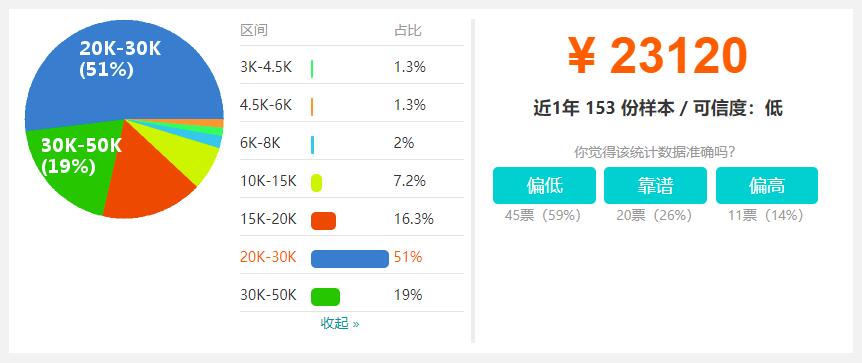
2018年北京大数据平均工资最新数据:¥ 23120/月,取自 153 份样本。(来源于职友集)
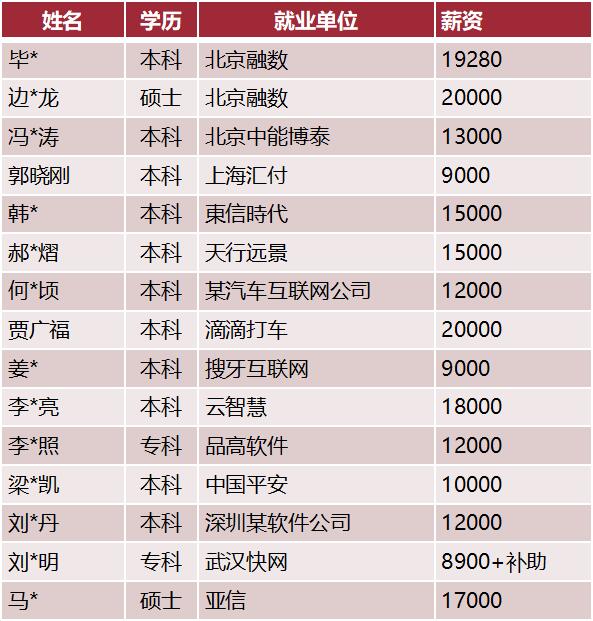
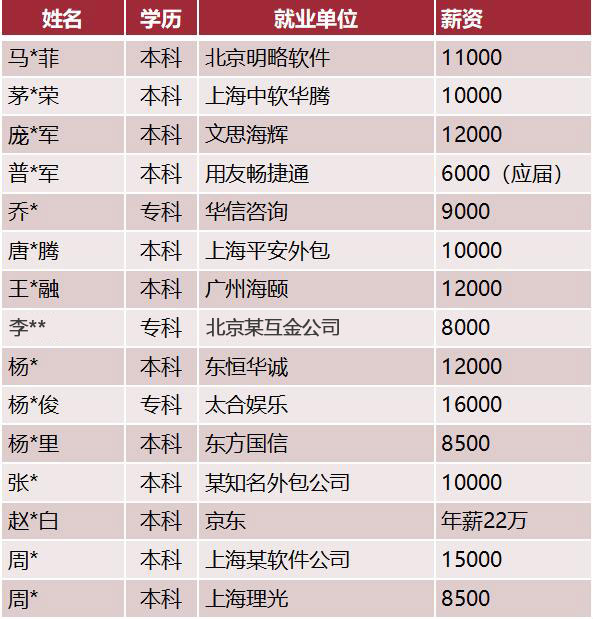
大讲台大数据·毕业学员平均月薪12K
越来越多的·Java|PHP|C++|.NET程序员转向大数据
已有一技傍身,却感觉涨薪困难?想进大公司却希望渺茫?物以稀为贵,你会的别人不会,这才是跳槽拿高薪的筹码!
真正的智者,应在努力的同时懂得审时度势,人才市场上稀缺性往往比能力更重要。据统计,到2020年,国内将会缺少100万懂得如何利用大数据来帮助公司做出有效决定的专业人员。而如何成为大数据时代的弄潮儿,掌握当下最紧缺的工具—Hadoop相关技能是关键!
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
学习“Hadoop+Spark+Storm”转行大数据需要什么技术基础?
有Java|PHP|C++|.NET其中一门编程语言基础;
对大数据开发有强烈的学习兴趣,能完成课程要求的课后练习;
想转型大数据领域的开发人员;
就业特训营·瞄准大型互联网公司的招聘需求
专家团队·一线师资无保留亲授
一线师资无保留亲授,4个月16周64次直播128小时 多名实战派老师组团研发授课和视频,累积课时640+

Felix
知名互联网众包服务平台
大数据高级架构师
国内知名众包服务平台大数据高级架构师,8年一线开发及项目管理经验,4年以上大数据系统架构及分析处理经验,骨灰级大数据玩家。曾就职于国内某TOP5的电信相关业务公司,负责对手机信息收集处理工作,对于Hadoop、Storm、Spark有较深研究。搭建、维护过上百节点集群,处理过PB级数据。 因技术出色,多次在知名企业内部进行大数据技能培训,对一线企业大数据方面的技能需求非常了解。

杨俊
原某广电数据咨询公司
大数据高级架构师
原某广电数据咨询公司大数据高级架构师 资深Java玩家,大数据技术狂热者。曾在北京某广电数据咨询公司担任大数据高级架构师,6年以上大数据实操经验, 经历过10个以上的重量级大数据项目。Hadoop源码级技术大咖,熟练使用Hadoop、Hive、HBase等各大主流组件。谦虚亲和,崇尚实操至上的教学理念。受到学员一致好评。

荣志坤
国内TOP5的视频网站
大数据资深工程师
资深全栈工程师,从业时间6年,先后服务于三家国内外上市公司,目前在国内TOP5的视频网站任大数据小组Leader。参与或负责过大型CDN文件传输系统,电信计费系统、大数据分析系统、中间件等多个重量级项目。精通Java、Python、Shell,熟悉Web应用开发。专注于大数据产品的研发和设计,能够熟练使用Hadoop、Hive、SQL来分析海量数据为决策提供依据。 技术狂,崇尚解决问题是开发人员的使命。

李大明
北大硕士、前百度工程师
大讲台金牌讲师
北大硕士,曾服务于百度、GREE、中软等多家优秀企业。数学功底深厚,精通数据结构和算法,在大流量、高并发互联网项目架构及开发方面有很深的造诣。
项目截图·8个大型实战项目
独特的混合式特训·快速提升你的实战能力
葵花宝典·众多精品专题课

【专题课】实时数仓利器ClickHouse
本课程基于ClickHouse最新稳定版本进行讲解,着重讲解ClickHouse大数据技术理论与实战。课程全面包含ClickHouse核心理论、分布式集群部署、架构设计、数据实时查询、MergeTree表引擎底层设计、副本与分片读写原理、外部系统集成开发以及ClickHouse全流程大数据项目实战等内容,让大家从基础到实战快速掌握ClickHouse大数据分析技术。

Hbase核心技术与实战
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。HBase在Hadoop之上提供了类似于Bigtable的能力,适用于实时读写、随机访问超大规模数据集。HBase不同于一般的关系数据库,它将大而稀疏的表放在服务器集群上,适合于非结构化数据存储的场景。

Kafka核心技术与实战
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark、Flink都支持与Kafka集成。

Flink电商运营项目实战
本课程基于某电商公司运营实时分析系统(2B),对Flink进行系统讲解。通过本课程的学习,既能获得Flink企业级真实项目经验,也能深入掌握Flink的核心理论知识,还能获得Flink在生产环境中安装、部署、监控的宝贵经验,从而深入掌握Flink技术。

大数据基础:Java强化班
本课程是由猎豹移动大数据架构师,根据Java在公司大数据开发中的实际应用,精心设计和打磨的大数据必备Java课程。通过本课程的学习大数据新手能够少走弯路,以较短的时间系统掌握大数据开发必备语言Java,为后续大数据课程的学习奠定了坚实的语言基础。

ElasticSearch核心技术与项目实战
本课程为ElasticSearch6.6视频搜索项目实战课程,项目基于Java开发,通过视频搜索项目案例的方式讲解Elasticsearch分布式搜索引擎中的核心技术,学员学习本课程以后可以初级实现类似优酷视频搜索项目。
学习动态

皮皮鹏刚刚学习了【系】走进大讲台 掀开职场新希望
大数据仓库项目实战2026/03/14 00:39:28

181****8506刚刚学习了【系】走进大讲台 掀开职场新希望
数据分析:Python语法基础2026/01/11 16:58:08

班诺刚刚学习了【系】走进大讲台 掀开职场新希望
Flink电商运营项目实战2025/12/22 09:49:12
皮皮鹏刚刚学习了【系】走进大讲台 掀开职场新希望
360度学透MySQL2026/03/02 16:14:32
班诺刚刚学习了【系】走进大讲台 掀开职场新希望
人工智能:深度学习应用实践2025/12/22 09:51:02
班诺刚刚学习了【系】走进大讲台 掀开职场新希望
Hbase核心技术与实战2025/12/22 09:47:46